





by Ray Bernardi
I’m old. Let’s get that established right up front. I have been around longer than sand, or at least that’s how it feels sometimes. You would think someone who has been in the industry for as long as I have would have a simple answer to a simple question. What is source code management? My reply? Well, that depends.
I could throw out the technical definition. It’s typically software that’s designed for source code management (SCM) or it’s a version control system (VCS) or a revision control system (RCS) and leave it at that. That doesn’t tell you much.
Remember, I established the fact that I am old. I come from System/34, System/38 and even mainframes before that. I grew up on these IBM midrange machines and I have been here for the old and new methodologies.
In the beginning, the earth cooled and the dinosaurs came. At that time, source control was simple. If you were going to change it, make a copy of it before you do. That was about it. What else did you need?
Of course that led to a few issues. Code regression being the big one. I followed the rules. I made a backup copy. I made all my changes. I put my code into production following the check list, and a day later, someone changing the same program did the same thing. The only problem was, they wiped my changes. They started with the same code as me. The code in production. We never saw the conflict until it was too late.
So we adapt. Making a copy isn’t enough. We need to have a common area so people can tell that someone is working on a program so we don’t regress. Well, that’s a little better. At least there’s some exposure to what’s going on, but it’s still not great. Think emergency change. Now what? Go around this? How do you notify and avoid regression then?
OK, remember we are evolving here. Let’s add a little more control, lets add a process we will call checkout. That will solve everything. We can even automate this process a little. Take a menu option, the system will write a record in a file saying you checked something out, and it can copy the source to a development area for you. Neat.
Now, because we have a file tracking checkouts, we can add conflict resolution. We can be sure an emergency change doesn’t create a regression in our code. We still need to jump through a lot of hoops to do this, like a second checkout, two working versions of source, a signoff on the conflict, a merge of code to avoid the regression and so on. It’s a bit of work but at least we are not losing code anymore.
If you’re old like me, you recognize the discussion above. It’s really IBM i-centric. It’s what we now call the pessimistic checkout model. Pessimistic because it locks source, and makes concurrent development difficult. Possible yes, but still, difficult.
Imagine working on your application. You might have a project that’s developing the next release, one for ongoing day to day maintenance, one for a minor enhancement, a few bug fixes happening, and one for a new feature being added to the existing version.
That’s ok as long as the programs you are changing don’t overlap much. Wait, we said new release work is being done. Unless you are renaming everything you work on, I think there might be a lot of overlap in that project.
In the scenario above, pessimistic checkout can work, but in the end, you’ll feel like a trained poodle after all the hoops you’ll need to jump through. If you enjoy being a trained poodle, you can stop reading here, if you’d like to hear about a better way? Read on.
I’m old. We established that already. I’m old but I can learn new tricks. The pessimistic checkout model above made you laugh if you are an open systems developer. You can’t even imagine how that process could work. It’s clunky at best and you can see how it would severely limit concurrent development.
For years we have been talking about becoming agile in the IBM i world. The term DevOps was coined. Marry development and operations using automation, that’s DevOps. It’s really about becoming agile. Most shops are looking at automation and are on the DevOps road. Modernize how you handle source as well. Adopt a new way, a new culture, unify your teams. It’s really possible.
ARCAD does pessimistic checkouts. It’s from the IBM i world. It’s old too, been around for 25+ years, but like me, it can learn new tricks. Old doesn’t mean stagnant. ARCAD is mature cutting edge technology that allows you to choose your source control system. Want to become truly agile? Put your IBM i code in a GIT repository. Start using a copy/modify/merge process instead of the pessimistic model described above. Did you know that’s possible?
It’s pretty easy to get your code in GIT. I have done a prior blog on that so I won’t cover it here again, but once your code is there, wow.
You create branches when you work. There is no checkout. You can have as many branches as you’d like. A branch for the new release, a branch for the new feature, a branch for a hotfix and so on. All the branching is done locally on the developers PC so it’s fast and easy. When you’re done developing, you push the branch up to a remote repository server. There, the change can be reviewed and accepted, and merged into the origin or main branch. During that merge, automatic conflict resolution is performed. If there is a conflict it is displayed and it can be dealt with easily. No regression of code happens.
Here is a typical workflow when using GIT for source control:
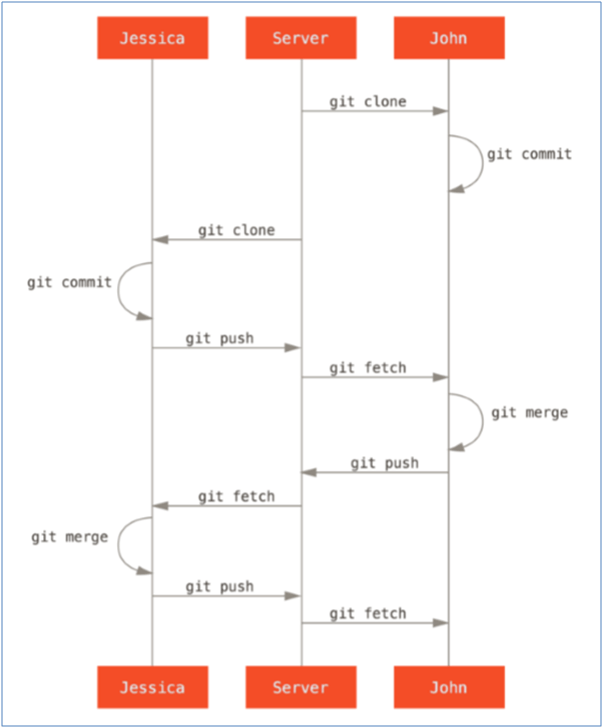
Down the middle is the remote server with the central repository. We have two developers in this example, Jessica and John. John starts by cloning the repository to his PC. He gets a full repository. That means he has everything he needs to develop and branch independently from the remote server. That means the operations are fast and you can work offline.
John starts his changes to PGM001 and does a local commit. Basically, he is saying I like that change, make it part of my local branch. Then Jessica clones the repository. She does not have Johns work yet. He has not pushed yet.
Jessica is a faster worker than John. She changes PGM001 does a local commit, likes what she sees and she does a push back to the remote repository. Her change is reviewed accepted and merged with the origin. That change is done.
John, being the good developer he is, is ready to push, but before he does, he performs a fetch. He is seeing if there are any changes since he started development. During that fetch he gets a conflict on PGM001. He merges Jessica’s change into his code and resolves any conflict. There will only be a conflict if they both changed the same lines of code.
John now pushes his change back to the remote server. He has included Jessica’s change. There is no regression. There was no hoop to jump through. Concurrent development happened on an IBM i source and nothing was lost. There were no bottlenecks in this scenario. That’s agile.
This methodology isn’t new to open systems developers. They have always worked this way. Us dinosaurs in the IBM i world are catching up. Take a look at this example:
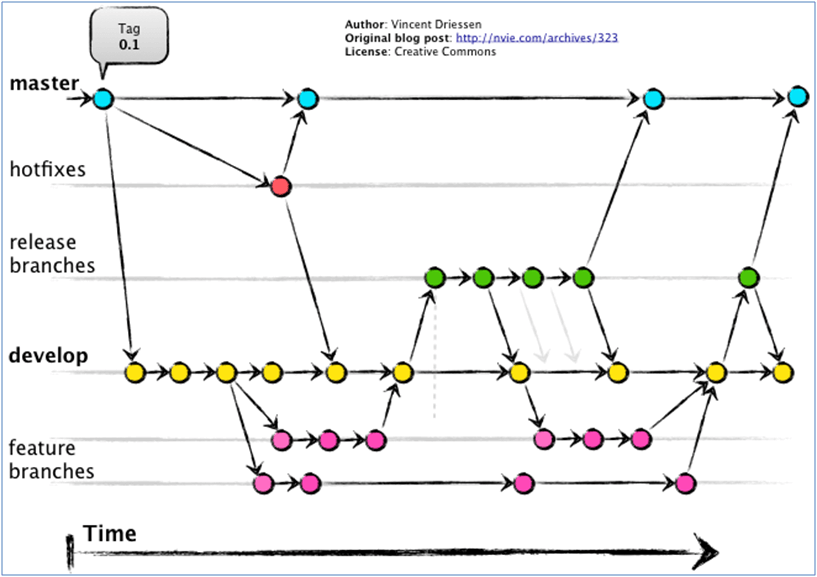
In this example we have hotfixes, releases, features and development branches shown. This is more typical of a real world working shop. Yes, this source management solution scales up to match this level of complexity and it does it well. Each dot is a commit, each arrow is a fetch or a push. This is true flexibility in source management. You are not limited by a pessimistic checkout and development can flow easily.
So to get back on topic here, the question was, “What is source code management?”
My answer is, it depends. It depends on where you want to be and what your shop looks like. Are you modernizing? Then source code management will probably look like the GIT model talked about above. Do you do little development but need controls in place for auditing purposes? Then perhaps the pessimistic checkout model will work for you.
There’s a time and a place for both these models. You really need to decide what source code management means to you. You need to figure out where you are now, and where you want your shop to be in 5 years.
More and more I see people leaving the pessimistic model and moving toward modern source control. I feel fortunate that ARCAD is an open system, and allows me to use and learn these new methods and technologies. I like not being stuck in the past.
So, I may be a dinosaur in that I have been around a long time, but I sure don’t feel like one when I work on my IBM i. Using RDi, GIT, Jenkins, GitHub, and other modern tools keeps me feeling pretty young.
So to finally answer the question, what is source control…. It’s what you want it to be. You need to adopt the method that works for you and your team. You need to make that call. We can show you both ways to help you out.
Want to see Git used as source control on an IBM i? Book a demo today and we will setup a time to show you just that. You really will be amazed at how easy and flexible modern source control can be.
Or should I just say.. check it out??

About the author
Ray Bernardi, Senior Consultant, ARCAD Software
Ray is a 30-year IT veteran and currently a Pre/Post Sales technical Support Specialist for ARCAD Software, international ISV and IBM Business Partner. He has been involved with the development and sales of many cutting edge software products throughout his career, with specialist knowledge in Application Lifecycle Management (ALM) products from ARCAD Software covering a broad range of functional areas including enterprise IBM i modernization and DevOps. In addition, Ray is a frequent speaker at COMMON and many other technical conferences around the world and has authored articles in several publications on the subject of application analysis and modernization, SQL, and business intelligence.

REQUEST A DEMO
Let’s talk about your project!
Speak with an expert